Active Learning for Text Classification in Python and Small-Text
What is Active Learning?

Active learning is an approach in machine learning that aims to improve the prediction model by iteratively selecting the most informative unlabeled data points for inclusion in the training set. This is done by training a predictor and using it to choose examples that will increase the chances of finding better configurations and improving the model’s accuracy. The process is repeated until a specified stopping criterion is met. Active learning is particularly useful in situations where labeled data is scarce, expensive, or requires domain expertise. It solves this problem by selecting unlabeled data points that are considered informative according to a query strategy and then having them labeled by an expert. [1, 2]
Active Learning Process:
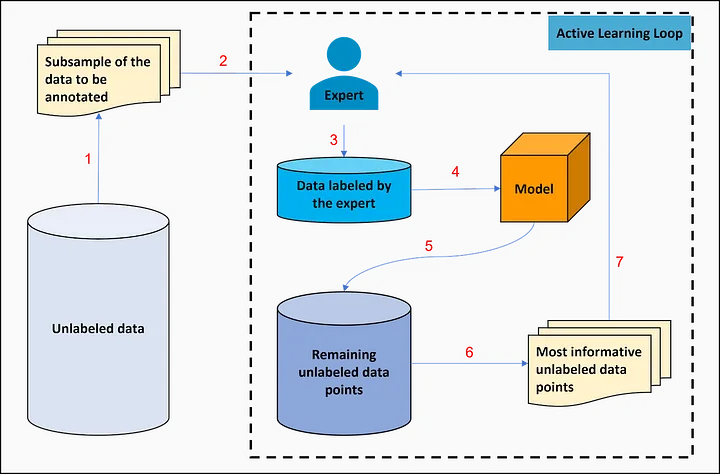
(Fig 1. Steps of active learning)
The steps to use active learning on an unlabeled dataset consist of:
- Selecting a subsample of the data to be annotated by the expert
- Manually annotating the selected data sample by the expert;
- Adding the data labeled by the expert to the labeled training set;
- Training the model on all the labeled data points;
- Making predictions on the remaining unlabeled data using the previously trained model; The model is used to score and rank the remaining unlabeled data points based on their informativeness.
- Selecting the most informative unlabeled data points to be annotated by the expert; These data points are chosen based on a query strategy that maximizes the expected reduction in prediction error.
- Repeating from step 2 to step 6 until the until a specified stopping criterion is met; The stopping criterion can be based on various factors, such as a fixed number of iterations, the performance of the model on the validation set, or a threshold for the amount of improvement achieved in model performance.
By iteratively selecting the most informative unlabeled data points for labeling and incorporating them into the training set, active learning aims to achieve high model performance with less labeled data than would be required by traditional supervised learning approaches.
About the Small-Text Library:
Small-Text provides state-of-the-art Active Learning for Text Classification. Several pre-implemented Query Strategies, Initialization Strategies, and Stopping Critera are provided, which can be easily mixed and matched to build active learning experiments or applications.
Small-Text Features
- Provides unified interfaces for Active Learning so that you can easily mix and match query strategies with classifiers provided by sklearn, Pytorch, or transformers.
- Supports GPU-based Pytorch models and integrates transformers so that you can use state-of-the-art Text Classification models for Active Learning.
- GPU is supported but not required. In case of a CPU-only use case, a lightweight installation only requires a minimal set of dependencies.
- Multiple scientifically evaluated components are pre-implemented and ready to use (Query Strategies, Initialization Strategies, and Stopping Criteria).
About this project:
This project consists of a notebook illustrating a simple example of how to perform Active Learning for text classification with small-text using sklearn models and the rotten tomatoes dataset.
Data preparation
To convert raw text data into a format usable by small-text, we use TF-IDF vectorizer, provided by sklearn, to extract features from text. Then, we use the SklearnDataset.from_arrays() helper function which constructs a SklearnDataset instance using the vectorizer, text, and labels.
Setting up the Active Learner
We start by constructing a PoolBasedActiveLearner instance which requires a classifier factory, a query strategy, and the train dataset.
To obtain a first model, we initialize the active learner by providing the true labels for 200 sentences. This corresponds to an initial labeling the real-world setting.
Active Learning Loop
The main active learning loop queries the unlabeled pool and thereby decides which documents are labeled next. We then provide the labels for those documents and the active learner retrains the model. After each query, we evaluate the current model against the test set and save the result.
It is worth noting that in this project we are implementing active learning as it is done in a scientific simulation. In reality, the label feedback would have been given by human annotators, and moreover, we would not be able to measure the test accuracy.